
ARGenSeg is a unified framework for visual understanding, segmentation, and generation. It supports semantic, instance, interactive, and zero-shot reasoning segmentation, as well as anomaly detection, by leveraging strong visual understanding capabilities.
Abstract
We propose a novel AutoRegressive Generation-based paradigm for image Segmentation (ARGenSeg), achieving multimodal understanding and pixel-level perception within a unified framework. Prior works integrating image segmentation into multimodal large language models (MLLMs) typically employ either boundary points representation or dedicated segmentation heads. These methods rely on discrete representations or semantic prompts fed into task-specific decoders, which limits the ability of the MLLM to capture fine-grained visual details. To address these challenges, we introduce a segmentation framework for MLLM based on image generation, which naturally produces dense masks for target objects. We leverage MLLM to output visual tokens and detokenize them into images using an universal VQ-VAE, making the segmentation fully dependent on the pixel-level understanding of the MLLM. To reduce inference latency, we employ a next-scale-prediction strategy to generate required visual tokens in parallel. Extensive experiments demonstrate that our method surpasses prior state-of-the-art approaches on multiple segmentation datasets with a remarkable boost in inference speed, while maintaining strong understanding capabilities.
Model Architecture and Workflow
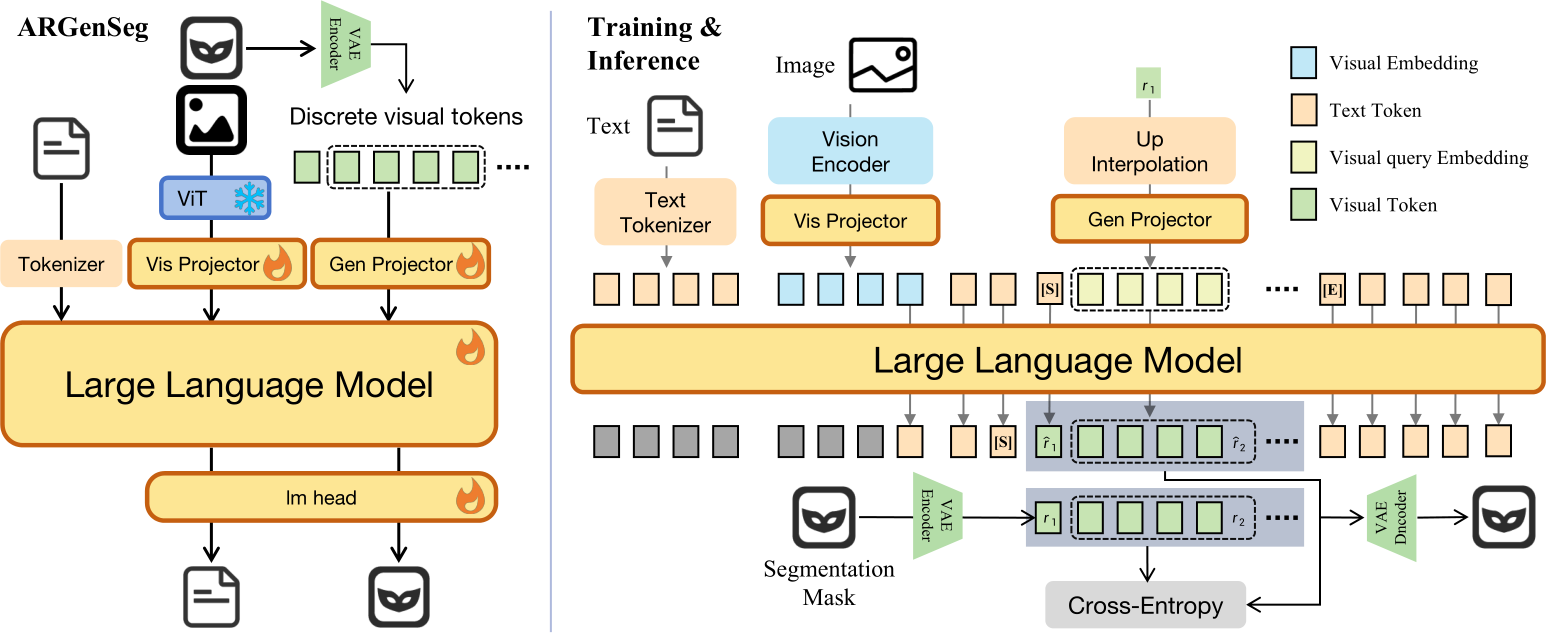
Left: ARGenSeg integrates image segmentation into the MLLM via an autoregressive image generation paradigm. A unified classification prediction head is used to generate both text and visual tokens.
Right: Visual tokens are generated in parallel using the next-scale prediction strategy. During training, a VAE encoder is used to construct supervision for cross-entropy loss. During inference, the VAE decoder reconstructs the image from the predicted visual tokens.
[S]/[E] denotes <gen_start>/<gen_end>.
Experiments
Quantitative Comparisons
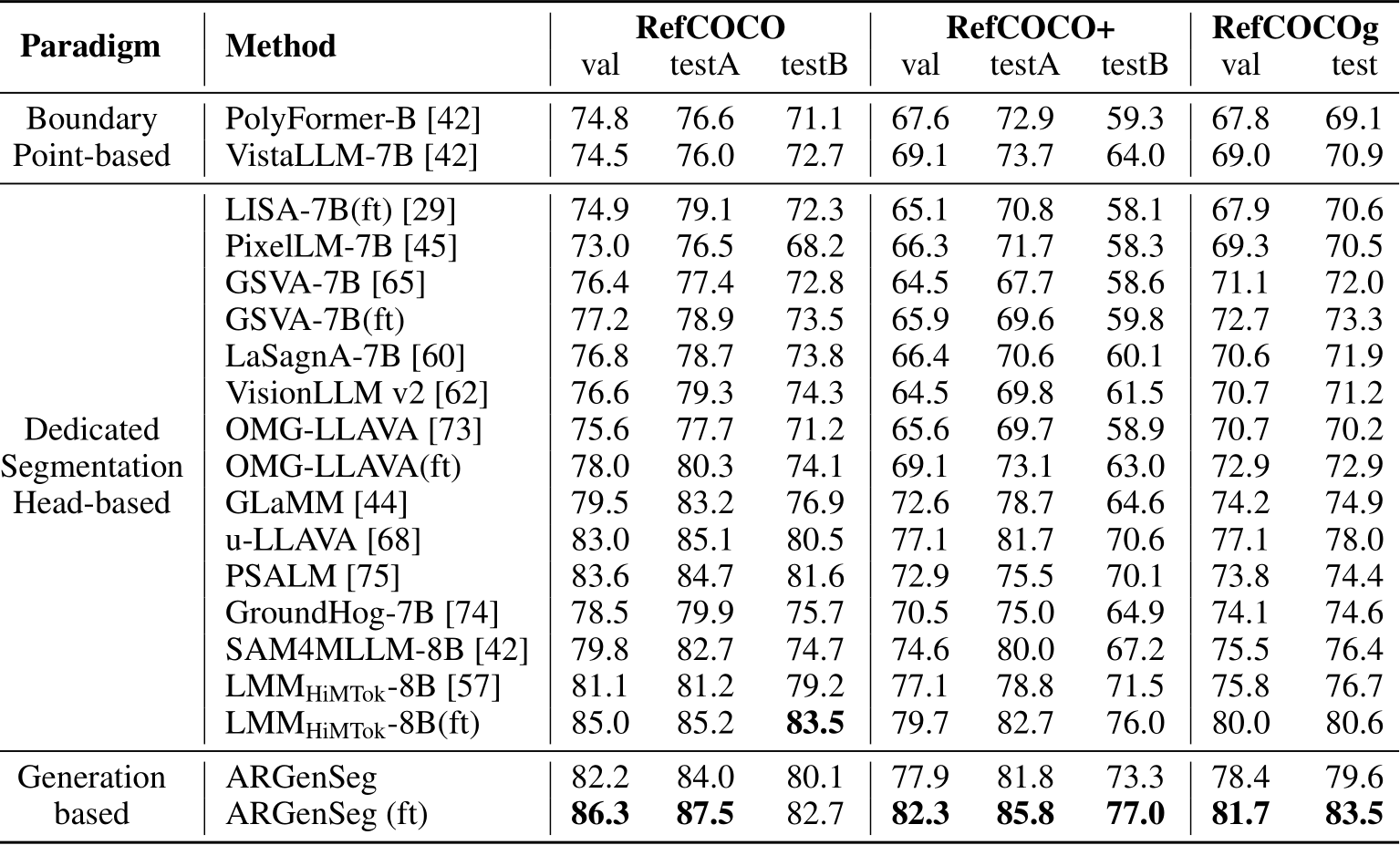
ARGenSeg consistently outperforms prior state-of-the-art methods on standard Referring Expression Segmentation (RES) benchmarks (RefCOCO/+/g). Notably, ARGenSeg achieves superior performance while using significantly less segmentation data (402K samples) compared to HiMTok (2.91M samples).
In a direct comparison with the single-scale visual tokenizer (pre-trained VQ-GAN from Janus), our multi-scale approach shows clear superiority.
Reporting on the validation split with gIoU as the metric, our method is proven to be both significantly faster and more robust, a benefit of its coarse-to-fine refinement strategy.

Qualitative Results

ARGenSeg first localizes the target object and then progressively refines its boundaries.

Top: Visualization of interactive segmentation. Points and scribbles are provided as visual prompts, while bounding boxes are input via text.
Bottom: Visualization results of instruction-based image generation. The model is trained on image generation data for only 50k iterations.
Poster

BibTeX
@article{wang2025argenseg,
title={ARGenSeg: Image Segmentation with Autoregressive Image Generation Model},
author={Wang, Xiaolong and Ru, Lixiang and Huang, Ziyuan and Ji, Kaixiang and Zheng, Dandan and Chen, Jingdong and Zhou, Jun},
journal={arXiv preprint arXiv:2510.20803},
year={2025}
}